四 线性分类
4.1 简介
4.1.1 思维导图
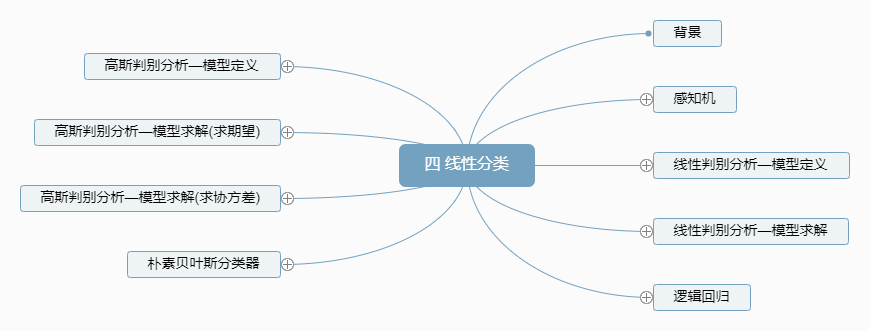
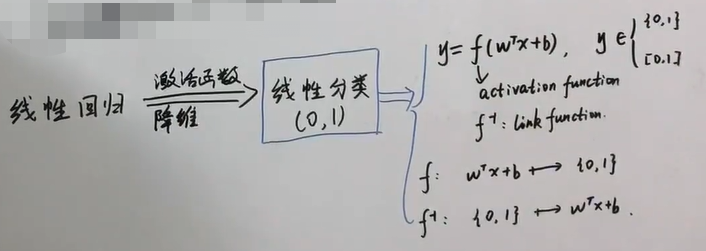
4.2.2 线性分类
线性回归$f(w,b)=w^{T}x+b, x \in {R^p}$是机器学习的核心。线性回归有三个属性:线性、全局性、数据未加工。其他机器学习的方式都是打破这三个属性的某一个或某几个而提出的。这这些和线性回归共同构成了机器学习方法。
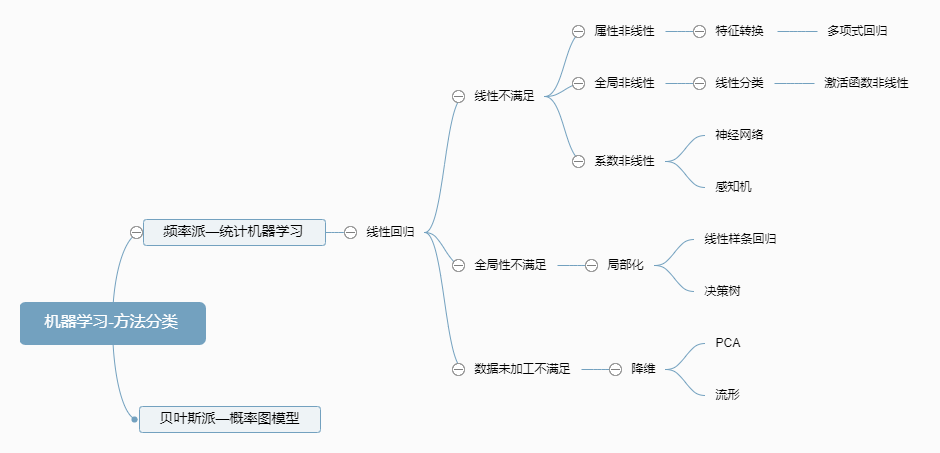
线性分类是打破了线性回归的全局非线性,线性回归一般是通过线性回归函数得出结论后直接输出,而线性分类是将线性回归得到的函数输入激活函数,激活函数是非线性的。
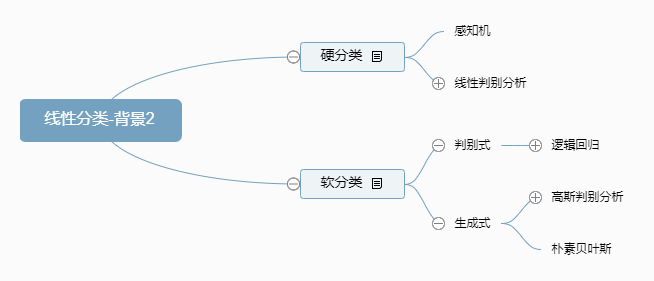
线性分类分为硬分类和软分类。其中硬分类是输出结果就一个集合,集合元素仅有两个0和1。而软分类输出结果则是0-1的一个区间,概率。软分类可以分为生成式和判别式。其中大名鼎鼎的logistic regression就是软分类,大家不要被它的名字误导了,虽然它叫回归,实际上它是用来处理分类问题的。
另外,我们还可以从降维的角度来考虑,原本是多维,然后降维或投影到0,1上来了
4.2 内容
4.2.1 背景
Background
线性回归是机器学习的核心。线性回归有三个属性:线性、全局性、数据未加工。其他机器学习的方式都是打破这三个属性的某一个或某几个而提出的。这这些和线性回归共同构成了机器学习方法。
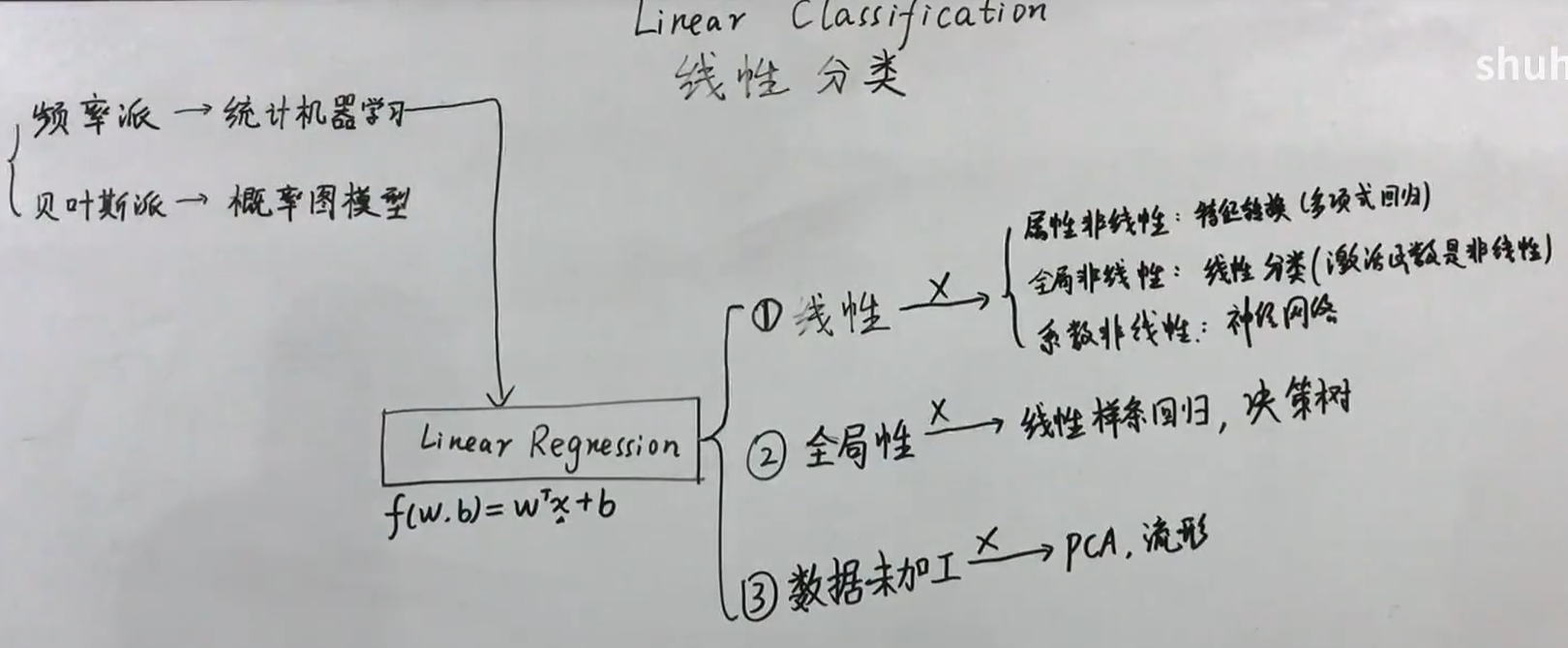
线性分类打破的是非线性,将得到的线性回归函数$f(w,b)=w^{T}x+b, x \in {R^p}$作为激活函数的输入,输出分类结果。分类又可以分为硬分类和软分类。
另外,我们还可以从降维的角度来考虑,原本是多维,然后降维或投影到0,1上来了.
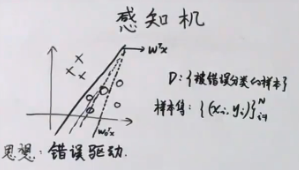
4.2.2 感知机
perceptron
属于,线性分类,硬分类方法
背景
思想:错误驱动
策略:Loss Function: 被错误分类点的个数
A 已知
B 求
分类成+1 -1两类
C 解
模型:

一般使用感知机算法有个前提,那就是数据线性可分,如果数据线性不可分,那就可以用pocket algorithm,它允许错误分类存在。
D 收获
感知机是线性分类硬输出的一种方法,其思想为错误驱动,就是使得被错误分类的样本点数最少。是一个很简单的算法,其实现算法使用随机梯度算法SGD进行,通过SGD确定$\Delta w$的大小。
需要实践下这个算法才有感觉,现在还没有感觉。主要问题出现在不理解的具体含义,需要一个实际的例子来说明。
4.2.3 线性判别分析LDA
Fisher
属于,线性分类,硬分类方法
背景
思想:
类内小、类间大,高内聚、低耦合,降维
从降维角度出发,将样本点投影到一维空间上去。
投影
向量$x _{i}$在向量$w$上的投影,可以写成数学式子:
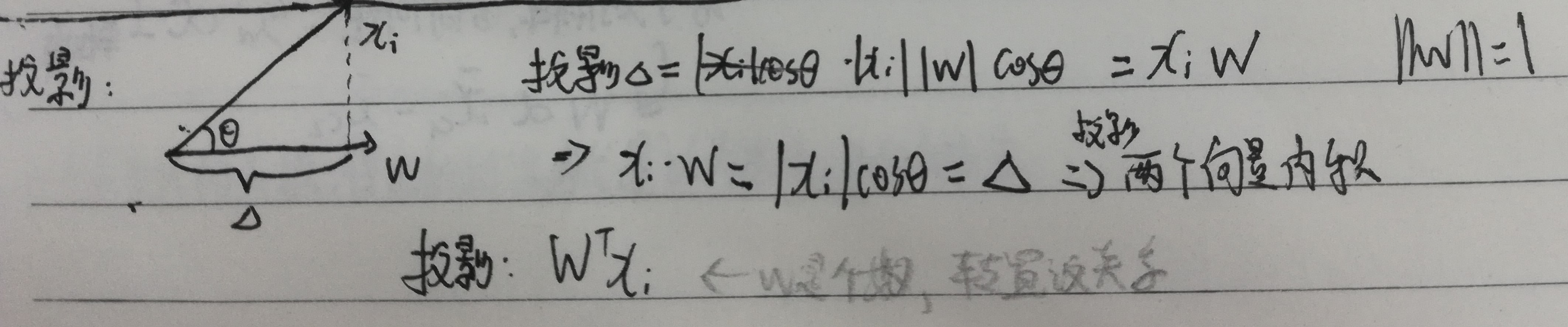
A 线性判别分析——模型定义
已知
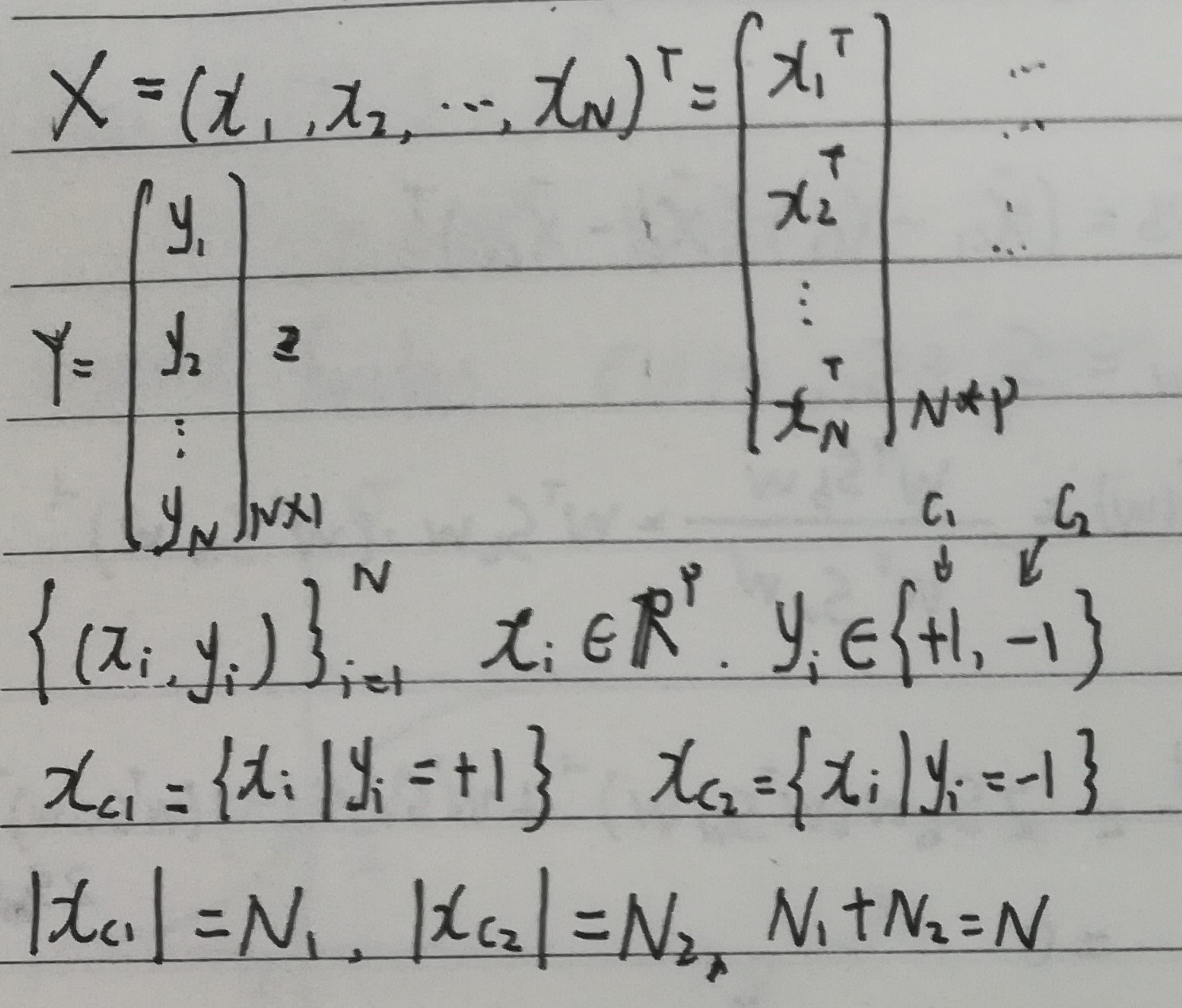
思想:类内小、类间大
求
投影后的目标函数$J(w)$,根据思想类内小、类间大可写出投影后目标函数$J(w)$:
目标函数:
$\bar z$是样本点投影均值,均值反映类间距离,类间距离越大,均值越大
$\bar s$是样本点投影方差,方差反映类内距离,类内距离越小,方差越小
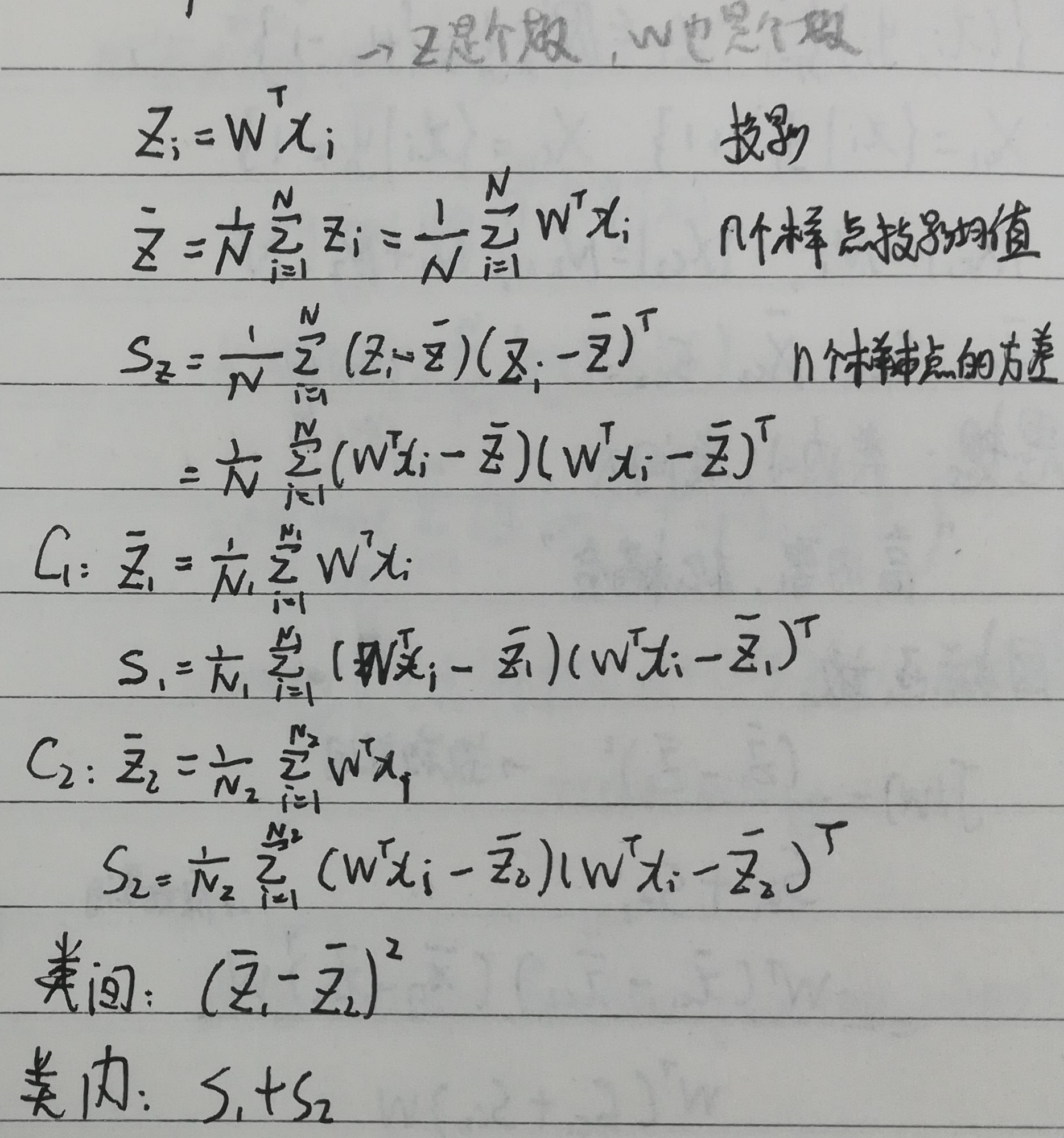
解
得出投影前最终$J(w)$模型为:
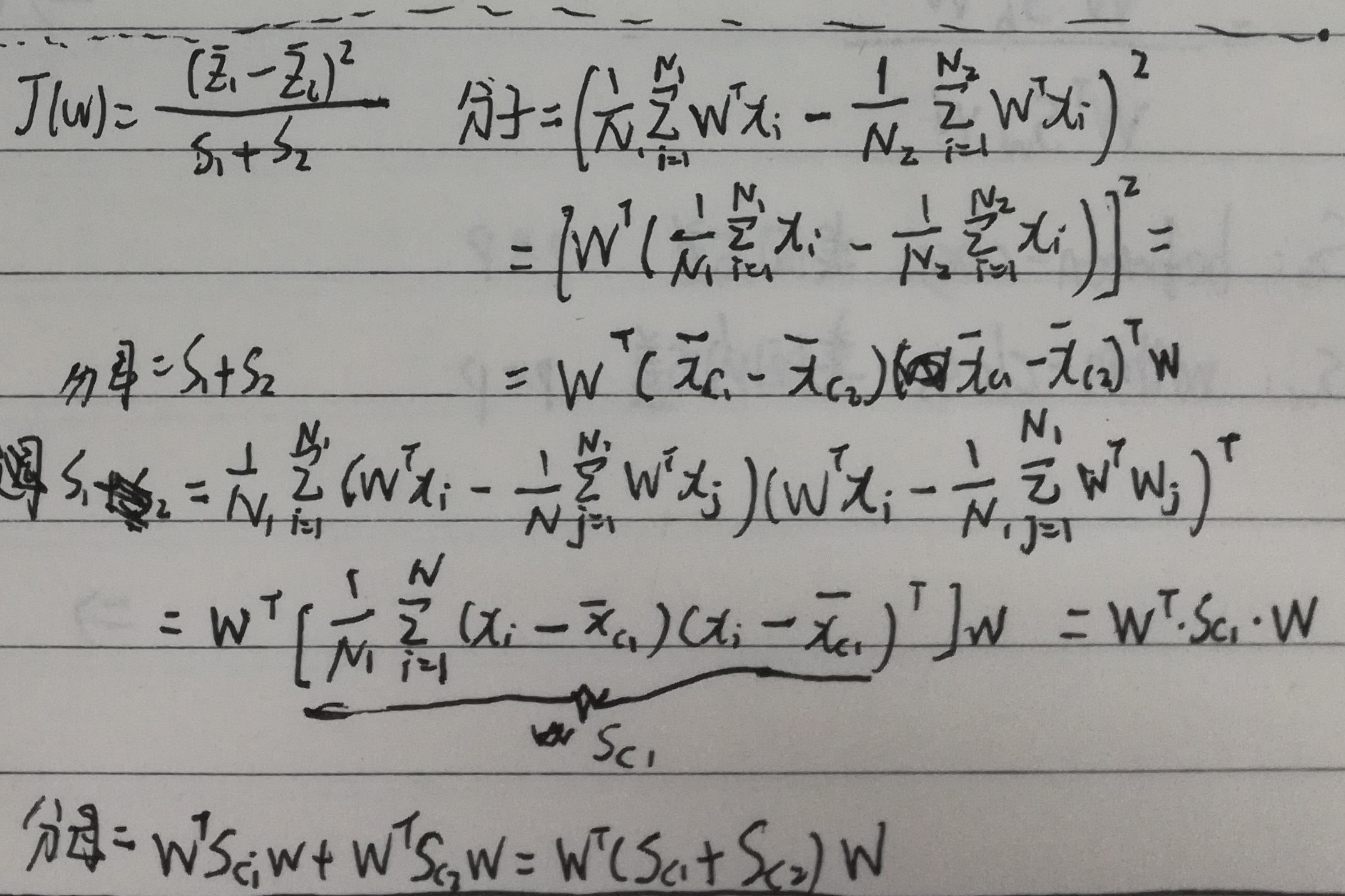
B 线性判别分析——模型求解
已知
$S_{b}$:between-class 类间方差 $p*p维$
$S_{w}$:between-class 类内方差 $p*p维$
求
解
其中,
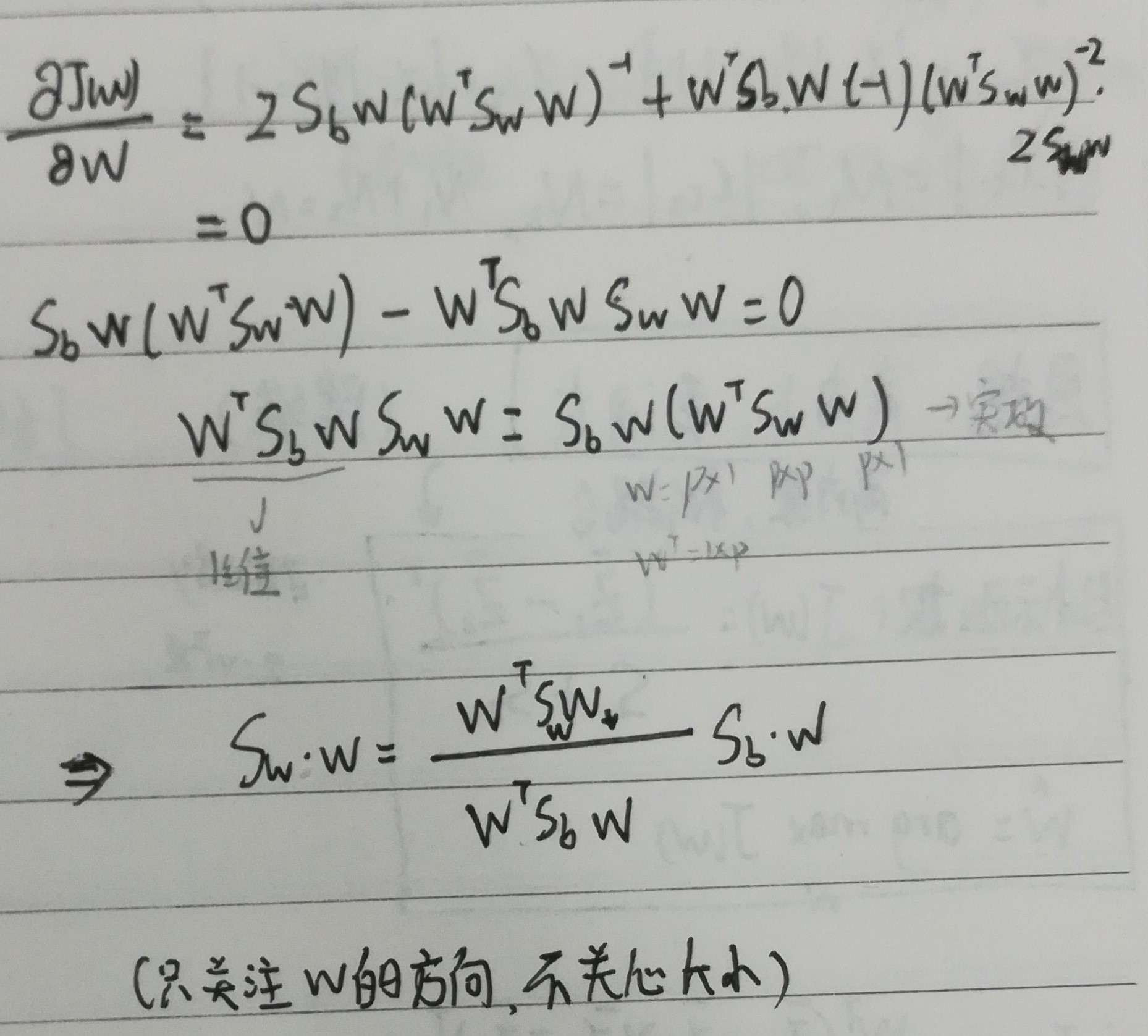
为什么只关注w的方向,不关心大小呢?
因为线性判别分析在应用中存在很大局限性,只需要理解下它的思想即可。
从维数可以看出 和 都是一个 $1*1$ 的实数

最后参数$w$的结果表明,的方向与:不同类内方差和 、不同类的均值差 有关。若为对角阵,各向同性,那么 的方向仅与 有关。
C 收获
线性判别分析属于线性分类硬输出的一种方式,线性判别分析的思想就是,将样本点投影到一维方向上去,使得投影之后的结果类内小、类间大。
4.2.4 逻辑回归
Logistic Regression
属于,线性分类,软分类,判别式方法
背景
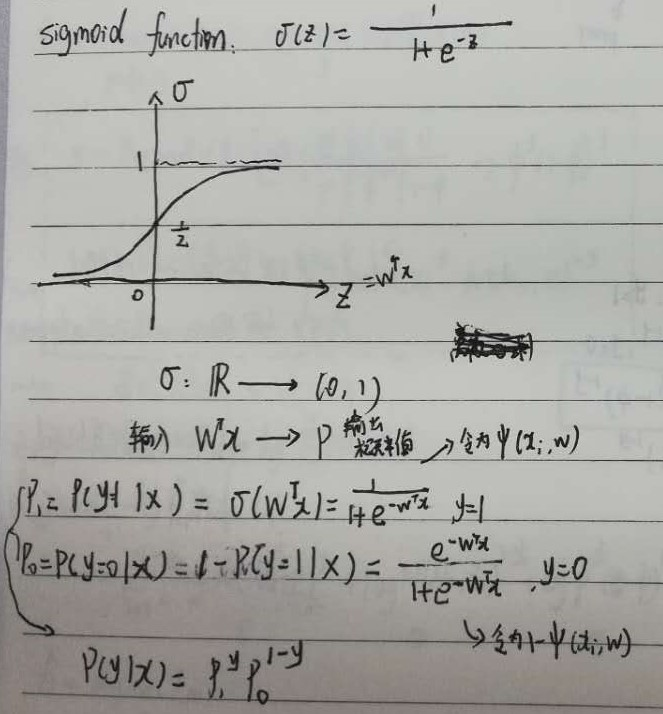
软分类之判别式方法,就是对$P(Y|X)$直接进行建模求解,求出$P(Y=1|X)和P(Y=0|X)$,其中$X$为输入数据,$Y$为输出分类。
有时候我们只要得到一个类别的概率,那么我们需要一种能输出 $[0,1]$ 区间的值的函数。考虑两分类模型,我们利用判别模型,希望对 $p(C|x)$ 建模,利用贝叶斯定理:
取 $a=\ln\frac{p(x|C_1)p(C_1)}{p(x|C_2)p(C_2)}$,于是:
上面的式子叫 Logistic Sigmoid 函数,其参数表示了两类联合概率比值的对数。在判别式中,不关心这个参数的具体值,模型假设直接对 $a$ 进行。
Logistic 回归的模型假设是:
于是,通过寻找 $ w$ 的最佳值可以得到在这个模型假设下的最佳模型。概率判别模型常用最大似然估计的方式来确定参数。
A 已知
引入sigmoid函数
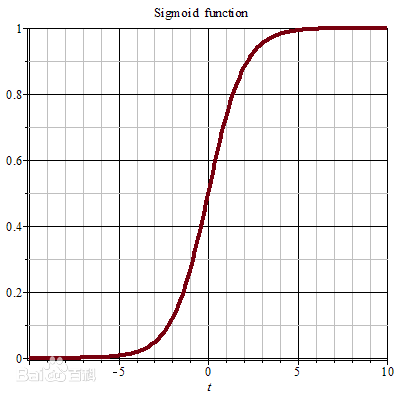
B 求
C 解
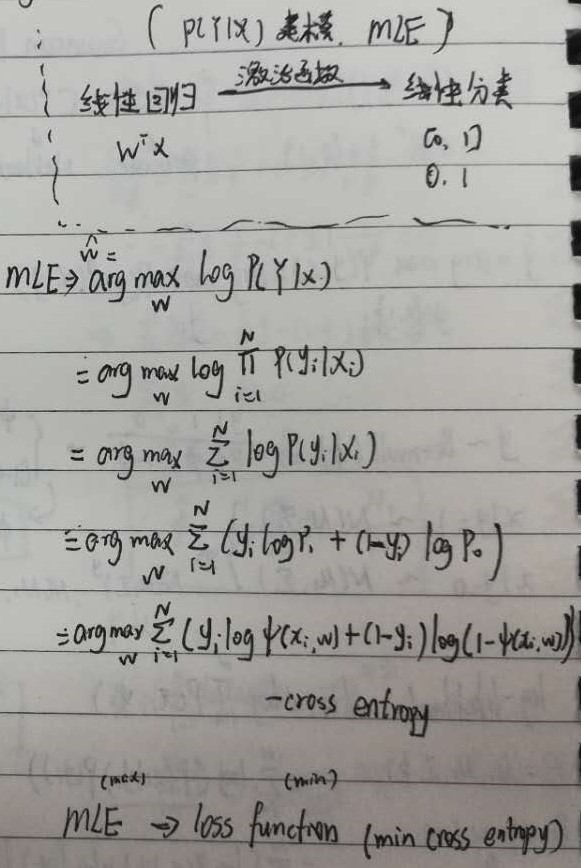
注意到,这个表达式是交叉熵表达式的相反数乘 $N$,MLE 中的对数也保证了可以和指数函数相匹配,从而在大的区间汇总获取稳定的梯度。
对这个函数求导数,注意到:
则:
由于概率值的非线性,放在求和符号中时,这个式子无法直接求解。于是在实际训练的时候,和感知机类似,也可以使用不同大小的批量随机梯度上升(对于最小化就是梯度下降)来获得这个函数的极大值。
D 收获
在解算过程中,有一个式子$P_{1} = P(y=1|x)=\sigma(w^{T}x)=\frac{1}{1+\exp(-w^{T}x)},y=1$,为什么能这么写呢?因为一个关于x的函数,得出的结果就认为是y=1的概率
4.2.5 高斯判别分析GDA
Gaussian Discriminant Analysis
属于,线性分类,软分类,生成式方法
背景
概率的生成模型,是对联合概率分布进行建模,然后利用MAP来获得参数的最佳值。不像判别模型直接求解$P(Y|X)$的值,生成模型更关心哪个值大,不关心具体值。
A 高斯判别分析—模型定义
已知
求
解
- $y\sim Bernoulli(\phi)$
- $x|y=1\sim\mathcal{N}(\mu_1,\Sigma)$
- $x|y=0\sim\mathcal{N}(\mu_0,\Sigma)$
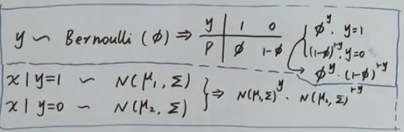
那么独立全同的数据集最大后验概率MAP可以表示为:
B.1 高斯判别分析—模型求解(求期望)
已知
草稿上x|y=0 ~ N(u2, Σ),实际上是x|y=0 ~ N(u0, Σ)

求
- $\phi$
- $\mu_1$
- $\mu_0$
解
首先对 $\phi$ 进行求解,将式子对 $\phi$ 求偏导:
然后求解 $\mu_1$:
由于:
求微分左边乘以 $\Sigma$ 可以得到:
- 求解 $\mu_0$,由于正反例是对称的,所以:
推导过程

B.2 高斯判别分析—模型求解(求协方差)
已知
最为困难的是求解 $\Sigma$
求
- $\Sigma$
解
最为困难的是求解 $\Sigma$,我们的模型假设对正反例采用相同的协方差矩阵,当然从上面的求解中我们可以看到,即使采用不同的矩阵也不会影响之前的三个参数。首先我们有:
在这个表达式中,我们在标量上加入迹从而可以交换矩阵的顺序,对于包含绝对值和迹的表达式的导数,我们有:
因此:
其中,$S_1,S_2$ 分别为两个类数据内部的协方差矩阵,于是:
这里应用了类协方差矩阵的对称性。
推导过程

C 收获
于是我们就利用最大后验的方法求得了我们模型假设里面的所有参数,根据模型,可以得到联合分布,也就可以得到用于推断的条件分布了。
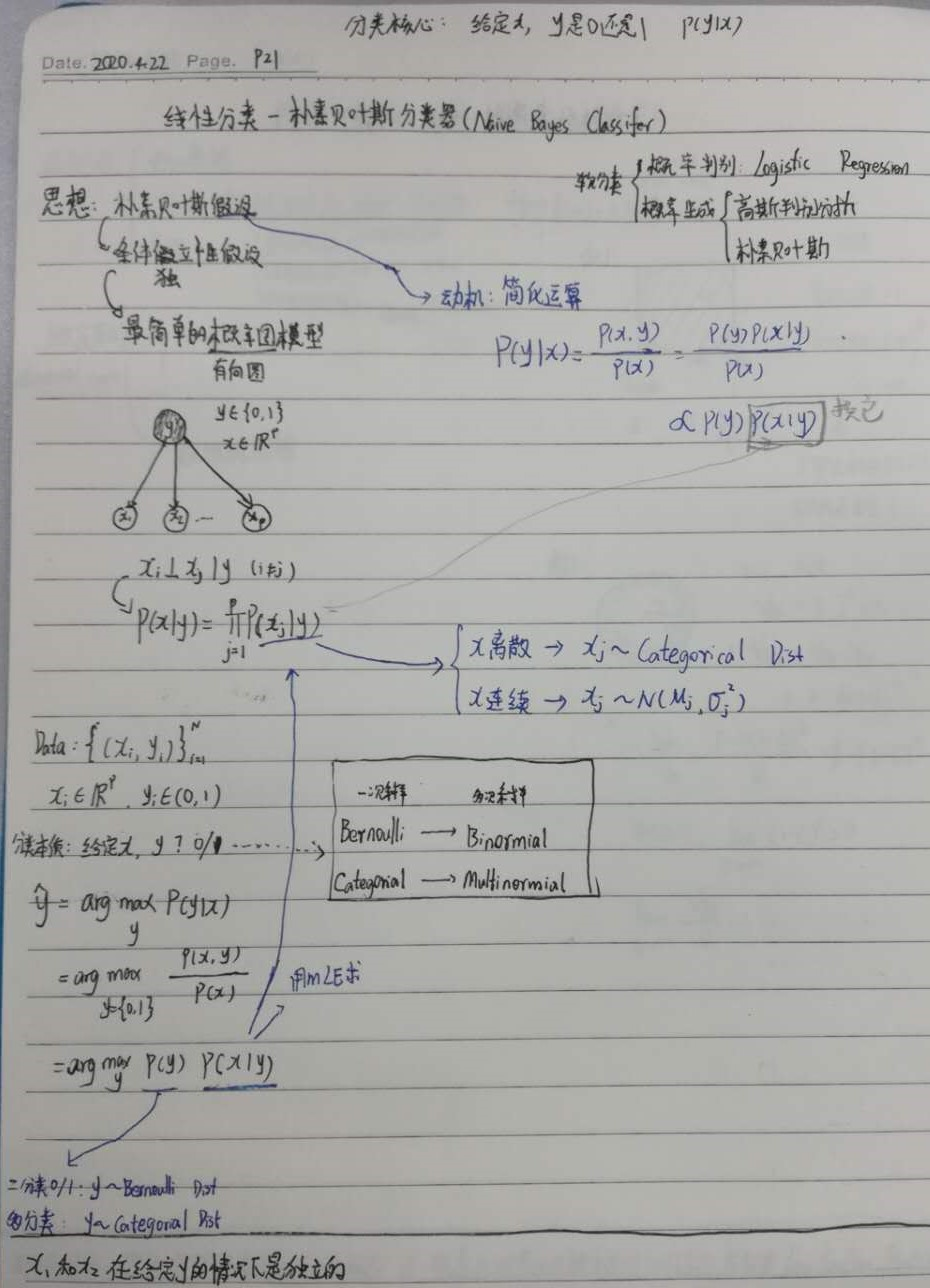
4.2.6 朴素贝叶斯分类器
naive Bayes Classifer
属于,线性分类,软分类,判别式方法
背景
思想:朴素贝叶斯假设->条件独立性假设->最简单的概率图(有向图)模型
做假设的动机:简化运算
主要是简化$P(X|Y)$
A 已知
上面的高斯判别分析的是对数据集的分布作出了高斯分布的假设,同时引入伯努利分布作为类先验,从而利用最大后验求得这些假设中的参数。
朴素贝叶斯对数据的属性之间的关系作出了假设,一般地,我们有需要得到 $p(x|y)$ 这个概率值,由于 $x$ 有 $p$ 个维度,因此需要对这么多的维度的联合概率进行采样,但是我们知道这么高维度的空间中采样需要的样本数量非常大才能获得较为准确的概率近似。
B 求
简化$P(X|Y)$
C 解
在一般的有向概率图模型中,对各个属性维度之间的条件独立关系作出了不同的假设,其中最为简单的一个假设就是在朴素贝叶斯模型描述中的条件独立性假设。
即:
于是利用贝叶斯定理,对于单次观测:
对于单个维度的条件概率以及类先验作出进一步的假设:
1.$x_i$为连续变量:$p(x_i|y)=\mathcal{N}(\mu_i,\sigma_i^2)$
2.为离散变量:类别分布(Categorical):
3.$p(y)=\phi^y(1-\phi)^{1-y}$
对这些参数的估计,常用 MLE 的方法直接在数据集上估计,由于不需要知道各个维度之间的关系,因此,所需数据量大大减少了。估算完这些参数,再代入贝叶斯定理中得到类别的后验分布。
D 收获
4.3 问题
4.3.1 线性分类之软输出的判别式和生成式区别是什么?
判别式,是直接对$P(Y|X)$进行求解,通过直接对$P(Y|X)$建模,求解出$P(Y=1|X)和P(Y=0|X)$的值。即,判别式更关心值的大小
生成式,不直接对$P(Y|X)$进行求解,而是利用贝叶斯公式,$P(Y|X){\rm{ = }}\frac{ {P(X|Y)P(Y)}}{ {P(X)}}$,通过计算$P(Y|X)P(Y)$来得到$P(Y|X)$。生成式更关心$P(Y=1|X)和P(Y=0|X)$谁大,不关心具体值。
4.4 小结
分类的本质核心任务:对于给定的x,输出y属于0类,还是属于1类。用数学描述就是求$P(y|x)$。
以下来自
tsyw的github库笔记
分类任务分为两类,对于需要直接输出类别的任务,感知机算法中我们在线性模型的基础上加入符号函数作为激活函数,那么就能得到这个类别,但是符号函数不光滑,于是我们采用错误驱动的方式,引入 作为损失函数,然后最小化这个误差,采用批量随机梯度下降的方法来获取最佳的参数值。而在线性判别分析中,我们将线性模型看作是数据点在某一个方向的投影,采用类内小,类间大的思路来定义损失函数,其中类内小定义为两类数据的方差之和,类间大定义为两类数据中心点的间距,对损失函数求导得到参数的方向,这个方向就是 $Sw^{-1}(\overline x{c1}-\overline x_{c2})$ ,其中 $S_w$ 为原数据集两类的方差之和。
另一种任务是输出分类的概率,对于概率模型,我们有两种方案,第一种是判别模型,也就是直接对类别的条件概率建模,将线性模型套入 Logistic 函数中,我们就得到了 Logistic 回归模型,这里的概率解释是两类的联合概率比值的对数是线性的,我们定义的损失函数是交叉熵(等价于 MLE),对这个函数求导得到 ,同样利用批量随机梯度(上升)的方法进行优化。第二种是生成模型,生成模型引入了类别的先验,在高斯判别分析中,我们对数据集的数据分布作出了假设,其中类先验是二项分布,而每一类的似然是高斯分布,对这个联合分布的对数似然进行最大化就得到了参数, 。在朴素贝叶斯中,我们进一步对属性的各个维度之间的依赖关系作出假设,条件独立性假设大大减少了数据量的需求。
参考文献
[1] shuhuai008. 【机器学习】【白板推导系列】【合集 1~23】. bilibili. 2019.
https://www.bilibili.com/video/BV1aE411o7qd?p=13
